Indeed, the author of the Replicability Index has been using observed power to determine the replicability of journal articles. His observed power estimates are HUGE (in the range of 0.75) and seem totally implausible to me, given the fact that I can hardly ever replicate my studies.
This got me thinking: Gelman and Carlin have shown that when power is low, Type M error will be high. That is, the observed effects will tend to be highly exaggerated. The issue with Type M error is easy to visualize.
Suppose that a particular study has standard error 46, and sample size 37; this implies that standard deviation is $46\times \sqrt{37}= 279$. These are representative numbers from psycholinguistic studies. Suppose also that we know that the true effect (the absolute value, say on the millisecond scale for a reading study---thanks to Fred Hasselman) is D=15. Then, we can compute Type S and Type M errors for replications of this particular study by repeatedly sampling from the true distribution.
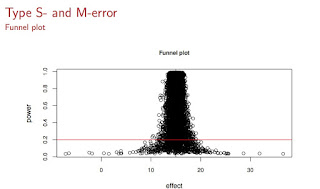
We can visualize the exaggerated effects under low power as follows (see below): On the x-axis you see the effect magnitudes, and on the y-axis is power. The red line is the power line of 0.20, which based on my own attempts at replicating my own studies (and mostly failing), I estimate to be an upper bound of the power of experiments in psycholinguistics (this is an upper bound, I think a more common value will be closer to 0.05). All those dots below the red line are exaggerated estimates in a low power situation, and if you were to use any of those points to estimate observed power, you would get a wildly optimistic power estimate which has no bearing with reality.
What does this fact about Type M error imply for Replicability Index's calculations? It implies that if power is in fact very low, and if journals are publishing larger-than-true effect sizes (and we know that they have an incentive to do so, because editors and reviewers mistakenly think that lower p-values, i.e., bigger absolute t-values, give stronger evidence for the specific alternative hypothesis of interest), then Replicability Index is possibly hugely overestimating power, and therefore hugely overestimating replicability of results.
I came up with the idea of framing this overestimation in terms of Type M error by defining something called a power inflation index. Here is how it works. For different "true" power levels, we repeatedly sample data, and compute observed power each time. Then, for each "true" power level, we can compute the ratio of the observed power to the true power in each case. The mean of this ratio is the power inflation index, and the 95% confidence interval around it gives us an indication (sorry Richard Morey! I know I am abusing the meaning of CI here and treating it like a credible interval!) of how badly we could overestimate power from a small sample study.
Here is the code for simulating and visualizing the power inflation index:
And here is the visualization:

In summary, we can never know true power, and if we are estimating it using observed power conditional on true power being extremely low, we are likely to hugely overestimate power.
One way to test my claim is to actually try to replicate the studies that Replicability Index predicts has high replicability. My prediction is that his estimates will be wild overestimates and most studies will not replicate.
Postscript
A further thing that worries me about Replicability Index is his sloppy definitions of statistical terms. Here is how he defines power:
"Power is defined as the long-run probability of obtaining significant results in a series of exact replication studies. For example, 50% power means that a set of 100 studies is expected to produce 50 significant results and 50 non-significant results."
[Thanks to Karthik Durvasula for correcting my statement below!]
By not defining power of a test of a null hypothesis $H_0: \mu=k$, as the probability of rejecting the null hypothesis (as a function of different alternative $\mu$ such that $\mu\neq k$) when it is false, what this definition literally means is that if I sample from any distribution, including one where $\mu=0$, the probability of obtaining a significant result under repeated sampling is the power. Which of course is completely false.
Post-Post Script
Replicability Index points out in a tweet that his post-hoc power estimation corrects for inflation. But post-hoc power corrected for inflation requires knowledge of the true power, which is what we are trying to get at in the first place. How do you deflate "observed" power when you don't know what the true power is? Maybe I am missing something.
7 comments:
>>power as the probability of rejecting the null hypothesis when it is false
In my opinion, the above suggested definition is also incorrect, and quite easily leads to thinking of hypotheses as dichotomous (a view that leads to the kinds of p-value “paradoxes”, we should be guarding against).
Power is better defined with respect to a particular discrepancy from the null hypothesis. So, power is for a particular μ’. Pow(μ’) is the probability of correctly rejecting the null hypothesis when the actual discrepancy is μ’.
By, this definition, there is no *single* power calculation with respect to a null hypotheses, although there might be a worst case scenario given what the practitioner considers to be a meaningful discrepancy.
Deborah Mayo has written a lot about this.
Sure; I agree that power of course has to be computed with respect to some specific mu, and so your definition is better. There is no single power calculation with respect to the null: agreed.
Rice defines power *of a test* as the probability that the null hypothesis is rejected when it is false. I should have put in *of a test* in my definition.
Mood et al provide a nice definition in terms of a power *function*, which is the point of your comment: "Given a null hypothesis, and let Gamma be the test of a null hypothesis. The power function of a test Gamma, denoted by Pi_Gamma(theta)...is the probability that H0 is rejected when the distribution from which the sample was obtained was parameterized by theta. The Mood et al definition seems better.
It's very hard to take Mayo seriously, because she writes fairly crazy stuff (such as equating p-values with something called "actual" Type I error).
>> nice definition in terms of a power *function*
Yes, I agree.
Also, the following is not immediately relevant to your post, so I own't waste too much ink on it. But you say:
>>It's very hard to take Mayo seriously, because she writes fairly crazy stuff (such as equating p-values with something called "actual" Type I error).
I would be very surprised if she said something like that. Do you have a reference for this particular comment?
Karthik,
Here is the comment where Mayo says that
"it would be OK so long as they reported the actual type I error, which is the P-value."
http://errorstatistics.com/2015/07/17/statistical-significance-according-to-the-u-s-dept-of-health-and-human-services-i/#comment-127764
Also see Morey's questions to Mayo in this thread and her responses.
When you posted that quote, it did take me by surprise. So, I decided to read the comment thread more carefully to see if this was just a terminological issue, and not really a conceptual one. And a careful reading of Mayo's response to seems to suggest to me that she intended "actual" to be in contrast to thresholded values, and not to "nominal". She was using "actual" in one of its normal English meanings, as opposed to a slightly more technical statistical sense. She writes later:
>>"I think it was my use of the word “actual” that got you confused. It only referred to the “attained” significance level or P-value, rather than a pre-designated cut-off (see the Lehmann-Romano quote).As discussed in the post that I linked to, the error probabilities associated with tests are hypothetical."
So, I am not sure that your allegation of her conceptual misunderstandings stands, though she could have shown more care in choosing her words.
There are of course other writings where she is absolutely clear about actual and nominal p-values (e.g., here), and this is true even in her correspondence with me via email. And unlike her blogposts (sometimes), her actual published work is really clear in my opinion wrt to deep/important statistical issues.
I'm happy to give her benefit of doubt as regards her understanding of these concepts. As you have seen, I also define things inaccurately from time to time.
However, there is more about her that I think hurts her credibility. She is now attacking the replication project without even acknowledging that it's a huge step forward.
I haven't read her blogposts on the replication project with sufficient care to be able to comment on it. But, my prior on the issue given (what I see as) her extreme clarity on other statistical/methodological issues is to grant her the benefit of the doubt.
I also wanted to thank you for maintaining this blog; it's been good fodder for the grey cells :).
Post a Comment