I wanted to post this reply to John Kruschke's blog post, but the blog comment box does not allow such a long response, so I posted it on my own blog and will link it in the comment box:
Hi John,
thanks for the detailed responses, and for the friendly tone of your response, I appreciate it.
I will try to write a more detailed review of the book to give some suggestions for the next edition, but I just wanted to respond to your comments:
1. Price: I agree that it's relative. But your argument assumes a US audience; people are often willing to pay outrageous amounts for things that are priced much more reasonably (and realistically) in Europe. Is the book primarily targeted to the US population? If not, the price is unreasonable. I cannot ask my students to buy this book when much cheaper ones exist. Even Gelman et al release slides that cover the entire or a substantial part of the BDA book. The analogy with calculus book is not valid either; Gilbert Strang's calculus book is available free on the internet, and there are many other free textbooks of very high quality. For statistics, there's Kerns, Michael Lavine's book, and for probability there are several great books available for free.
This book is more accessible than BDA and could become the standard text in psycholinguistics/psychology/linguistics. Why not halve the price and make it easier to get hold of? Even better, release a free version on the web. I could then even set it as a textbook in my courses, and I would.
2. Regarding the frequentist discussion, you wrote: "The vast majority of users of traditional frequentist statistics don't know why they should bother with taking the effort to learn Bayesian methods."
and
"Again, I think it's important for beginners to see the contrast with frequentist methods, so that they know why to bother with Bayesian methods."
My objection is that the criticism of frequentist methods is not the primary motivation for using Bayesian methods. I agree that people don't understand p-values and CIs. But the solution to that is to educate them so they understand them, the motivation for using Bayes cannot be that people don't understand frequentist methods
and/or abuse them. The next step would be to not use Bayesian methods because people who use it don't understand them and/or abuse them.
The primary motivation for me for using Bayes is the astonishing flexibility of Bayesian tools. It's not the only motivation, but this one thing outweighs everything else for me.
Also, even if the user of frequentist statistics realizes the problems inherent in the abuse of frequentist tools, this alone won't be sufficient to motivate them to move to Bayesian statistics. A more inclusive philosophy would be more effective: for some things a frequentist method is just fine (used properly). For other things you really need Bayes. You don't always need a laser gun; there are times when a hammer would do just fine (my last sentence does not do justice to frequentist tools, which are often really sophisticated).
3. "If anything, I find that adherence to frequentist methods require more blind faith than Bayesian methods, which to me just make rational sense. To the extent there is any tone of zealotry in my writing, it's only because the criticisms of p values and confidence intervals can come as a bit of a revelation after years of using p values without really understanding them."
I understand where you are coming from; I have also taken the same path of slowly coming to understand what the methodology was really saying, and initially I also fell into the trap of getting annoyed with frequentist methods and rejecting them outright.
But I have reconsidered my position and I think Bayes should be presented on its own merits. I can see that relating Bayes and freq. methods is necessary to clarify the differences, but this shouldn't run out of control. In my future courses that is the line I am going to take.
When I read material attacking frequentist methods *as a way to get to Bayes*, I am strongly reminded of the gurus in India who use a similar strategy to make their new converts believe in them and drive out any loyalty to the old guru. That is where my analogy to religion is coming from. It's an old method, and I have seen religious zealots espousing "the one right way" using it.
4. "Well, yes, that is a major problem. But I don't think it's the only major problem. I think most users of frequentist methods don't understand what a p value and confidence interval really are. "
Often, these are the same thing. They are abused by many people because they don't understand them. An example is psycholinguistics, where we routinely publish null results in low power experiments as positive findings. The people who do that are not abusing statistics deliberately, they just don't know that a null result is not informative in their particular settings. Journal editors (top journals) think that a lower p-value gives you more evidence in favor of the specific alternative. They just don't understand it, but they are not involved in deception.
The set of people who understand the method and deliberately abuse it is probably nearly the empty set. I don't know anyone in psycholinguistics who understands p-values and CIs and still abuses the method.
I'll write more later (and I have many positive comments!) once I've finished reading your 700+ page book! :)
Sunday, November 30, 2014
Tuesday, November 25, 2014
Should we fit maximal linear mixed models?
Recently, Barr et al published a paper in the Journal of Memory and Language, arguing that we should fit maximal linear mixed models, i.e., fit models that have a full variance-covariance matrix specification for subject and for items. I suggest here that the recommendation should not be to fit maximal models, the recommendation should be to run high power studies.
I released a simulation on this blog some time ago arguing that the correlation parameters are pretty meaningless. Dale Barr and Jake Westfall replied to my post, raising some interesting points. I have to agree with Dale's point that we should reflect the design of the experiment in the analysis; after all, our goal is to specify how we think the data were generated. But my main point is that given the fact that the culture in psycholinguistics is to run low power studies (we routinely publish null results with low power studies and present them as positive findings), fitting maximal models without asking oneself whether the various parameters are reasonably estimable will lead us to miss effects.
For me, the only useful recommendation to psycholinguists should be to run high power studies.
Consider two cases:
1. Run a low power study (the norm in psycholinguistics) where the null hypothesis is false.
If you blindly fit a maximal model, you are going to miss detecting the effect more often compared to when you fit a minimal model (varying intercepts only). For my specific example below, the proportions of false negatives is 38% (maximal) vs 9% (minimal).


In the top figure, we see that under repeated sampling, lmer is failing to estimate the true correlations for items (it's doing a better job for subjects because there is more data for subjects). Even though these are nuisance parameters, trying to estimate them for items in this dataset is a meaningless exercise (and the fact that the parameterization is going to influence the correlations is not the key issue here---that decision is made based on the hypotheses to be tested).
The lower figure shows that under repeated sampling, the effect (\mu is positive here, see my earlier post for details) is being missed much more often with a maximal model (black lines, 95% CIs) than with a varying intercepts model (red lines). The difference is in the miss probability is 38% (maximal) vs 9% (minimal).
2. Run a high power study.

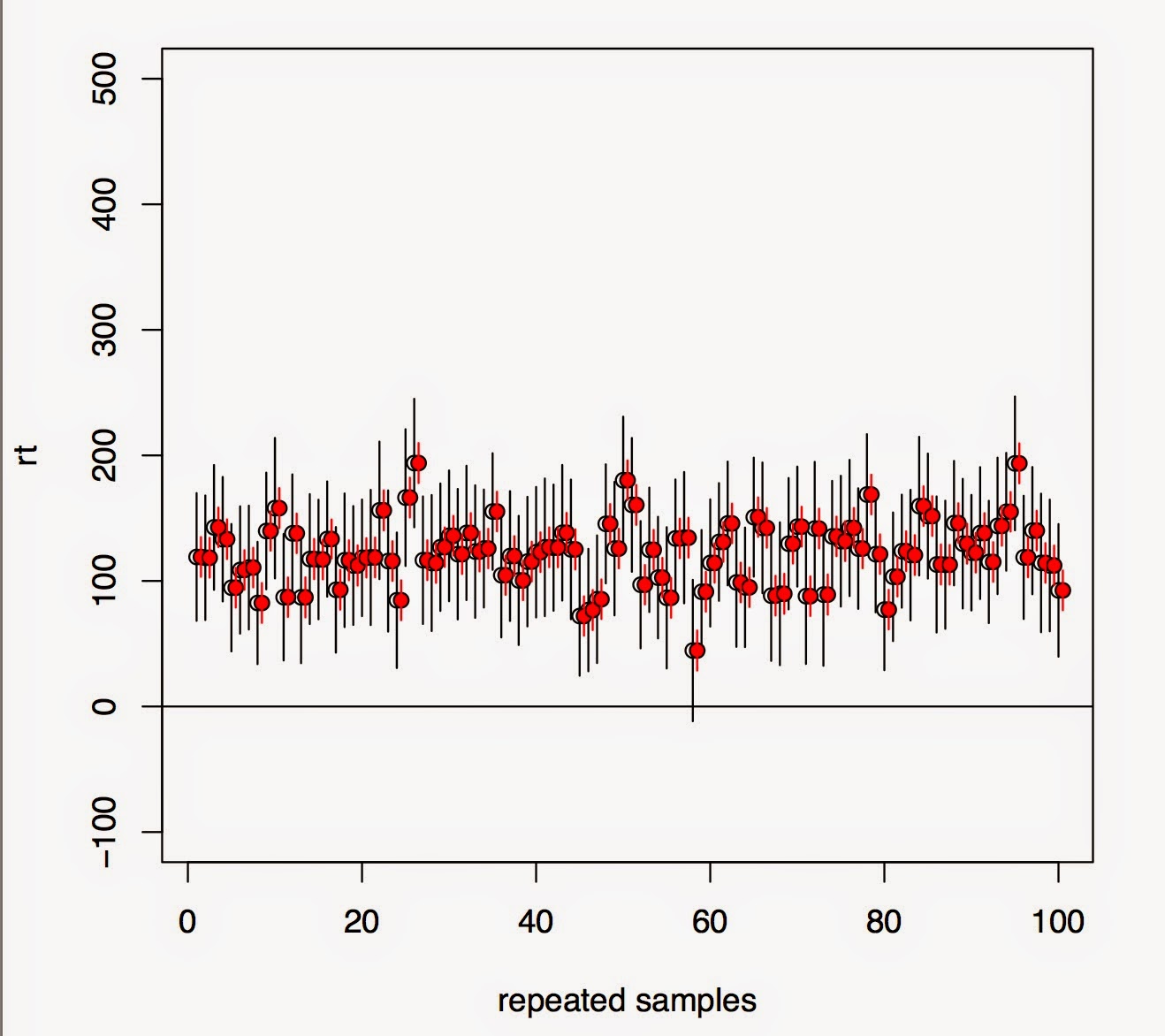
Now, it doesn't really matter whether you fit a maximal model or not. You're going to detect the effect either way. The upper plot shows that under repeated sampling, lmer will tend to detect the true correlations correctly. The lower plot shows that in almost 100% of the cases, the effect is detected regardless of whether we fit a maximal model (black lines) or not (red lines).
My conclusion is that if we want to send a message regarding best practice to psycholinguistics, it should not be to fit maximal models. It should be to run high power studies. To borrow a phrase from Andrew Gelman's blog (or from Rob Weiss's), if you are running low power studies, you are leaving money on the table.
Here's my code to back up what I'm saying here. I'm happy to be corrected!
https://gist.github.com/vasishth/42e3254c9a97cbacd490
I released a simulation on this blog some time ago arguing that the correlation parameters are pretty meaningless. Dale Barr and Jake Westfall replied to my post, raising some interesting points. I have to agree with Dale's point that we should reflect the design of the experiment in the analysis; after all, our goal is to specify how we think the data were generated. But my main point is that given the fact that the culture in psycholinguistics is to run low power studies (we routinely publish null results with low power studies and present them as positive findings), fitting maximal models without asking oneself whether the various parameters are reasonably estimable will lead us to miss effects.
For me, the only useful recommendation to psycholinguists should be to run high power studies.
Consider two cases:
1. Run a low power study (the norm in psycholinguistics) where the null hypothesis is false.
If you blindly fit a maximal model, you are going to miss detecting the effect more often compared to when you fit a minimal model (varying intercepts only). For my specific example below, the proportions of false negatives is 38% (maximal) vs 9% (minimal).
In the top figure, we see that under repeated sampling, lmer is failing to estimate the true correlations for items (it's doing a better job for subjects because there is more data for subjects). Even though these are nuisance parameters, trying to estimate them for items in this dataset is a meaningless exercise (and the fact that the parameterization is going to influence the correlations is not the key issue here---that decision is made based on the hypotheses to be tested).
The lower figure shows that under repeated sampling, the effect (\mu is positive here, see my earlier post for details) is being missed much more often with a maximal model (black lines, 95% CIs) than with a varying intercepts model (red lines). The difference is in the miss probability is 38% (maximal) vs 9% (minimal).
2. Run a high power study.
Now, it doesn't really matter whether you fit a maximal model or not. You're going to detect the effect either way. The upper plot shows that under repeated sampling, lmer will tend to detect the true correlations correctly. The lower plot shows that in almost 100% of the cases, the effect is detected regardless of whether we fit a maximal model (black lines) or not (red lines).
My conclusion is that if we want to send a message regarding best practice to psycholinguistics, it should not be to fit maximal models. It should be to run high power studies. To borrow a phrase from Andrew Gelman's blog (or from Rob Weiss's), if you are running low power studies, you are leaving money on the table.
Here's my code to back up what I'm saying here. I'm happy to be corrected!
https://gist.github.com/vasishth/42e3254c9a97cbacd490
Saturday, November 22, 2014
Simulating scientists doing experiments
Following a discussion on Gelman's blog, I was playing around with simulating scientists looking for significant effects. Suppose each of 1000 scientists run 200 experiments in their lifetime, and suppose that 20% of the experiments are such that the null is true. Assume a low power experiment (standard in psycholinguistics; eyetracking studies even in journals like JML can easily have something like 20 subjects). E.g., with a sample size of 1000, delta of 2, and sd of 50, we have power around 15%. We will add the stringent condition that the scientist has to get one replication of a significant effect before they publish it.
What is the proportion of scientists that will publish at least one false positive in their lifetime? That was the question. Here's my simulation. You can increase the effect_size to 10 from 2 to see what happens in high power situations.
Comments and/or corrections are welcome.
What is the proportion of scientists that will publish at least one false positive in their lifetime? That was the question. Here's my simulation. You can increase the effect_size to 10 from 2 to see what happens in high power situations.
Comments and/or corrections are welcome.
Subscribe to:
Posts (Atom)