These recordings are part of a set of videos that are available from the free four-week online course Introduction to Bayesian Data Analysis, taught over the openhpi.de portal.
Showing posts with label brms. Show all posts
Showing posts with label brms. Show all posts
Monday, January 30, 2023
Tuesday, October 04, 2022
Applications open: The Seventh Summer School on Statistical Methods for Linguistics and Psychology, 11-15 September 2023
Applications are open (till 1st April 2023( for the seventh summer school on statistical methods for linguistics and psychology, to be held in Potsdam, Germany.
Summer school website: https://vasishth.github.io/smlp2023/
Some of the highlights:
1. Four parallel courses on frequentist and Bayesian methods (introductory/intermediate and advanced)
2. A special short course on Bayesian meta-analysis by Dr. Robert Grant of bayescamp.
3. You can also do this free, completely online four-week course on Introduction to Bayesian Data Analysis (starts Jan 2023): https://open.hpi.de/courses/bayesian-statistics2023
Thursday, September 08, 2022

Friday, May 27, 2022
Summer School “Methods in Language Sciences” (16-20 August 2022, Ghent, Belgium): Registrations open
I was asked to advertise this summer school (I will be teaching a 2.5 day course on linear mixed modeling, and will give a keynote lecture on the use of Bayesian methods in linguistics/psychology). The text below is from the organizers.
Summer School “Methods in Language Sciences” 2022:
Registrations are open
Top quality research requires outstanding methodological skills. That is why the Department
of Linguistics and the Department of Translation, Interpreting and Communication of Ghent
University will jointly organize the (second edition of the) Summer School “Methods in
Language Sciences” on 16-20 August 2022.
This Summer School is targeted at both junior and senior researchers and offers nine multi-
day modules on various topics, ranging from quantitative to qualitative methods and
covering introductory and advanced statistical analysis, Natural Language Processing
(NLP), eye-tracking, survey design, ethnographic methods, as well as specific tools such
as PRAAT and ELAN. In 2022 we have a new module on Linear Mixed Models. All lecturers
are internationally recognized experts with a strong research and teaching background.
Because the modules will partly be held in parallel sessions, participants have to choose one
or two modules to follow (see the Programme for details). No prerequisite knowledge or
experience is required, except for Modules 2 and 9, which deal with advanced statistical data
analysis.
We are proud to welcome two keynote speakers at this year’s summer school: Shravan
Vasishth and Crispin Thurlow, who both also act as lecturers.
This is your opportunity to take your methodological skills for research in (applied)
linguistics, translation or interpreting studies to the next level. We are looking forward to
meeting you in Ghent!
Wednesday, March 23, 2022
New paper: Some right ways to analyze (psycho)linguistic data
New paper (under review):
Title: Some right ways to analyze (psycho)linguistic data
Abstract:
Much has been written on the abuse and misuse of statistical methods, including p-values, statistical significance, etc. I present some of the best practices in statistics using a running example data analysis. Focusing primarily on frequentist and Bayesian linear mixed models, I illustrate some defensible ways in which statistical inference—specifically, hypothesis testing using Bayes factors vs. estimation or uncertainty quantification—can be carried out. The key is to not overstate the evidence and to not expect too much from statistics. Along the way, I demonstrate some powerful ideas, the most important ones being using simulation to understand the design properties of one’s experiment before running it, visualizing data before carrying out a formal analysis, and simulating data from the fitted model to understand the model’s behavior.
PDF: https://psyarxiv.com/y54va/
Summer School on Statistical Methods for Linguistics and Psychology, Sept. 12-16, 2022 (applications close April 1)
The Sixth Summer
School on Statistical Methods for Linguistics and Psychology will be
held in Potsdam, Germany, September 12-16, 2022. Like the previous
editions of the summer school, this edition will have two frequentist
and two Bayesian streams. Currently, this summer school is being planned
as an in-person event.
The application form closes April 1, 2022. We will announce the decisions on or around April 15, 2022.
Course fee: There is no fee because the summer school is funded by the Collaborative Research Center (Sonderforschungsbereich 1287). However, we will charge 40 Euros to cover costs for coffee and snacks during the breaks and social hours. And participants will have to pay for their own accommodation.
For details, see: https://vasishth.github.io/
Curriculum:
1. Introduction to Bayesian data analysis (maximum 30 participants). Taught by Shravan Vasishth, assisted by Anna Laurinavichyute, and Paula Lissón
This course is an introduction to Bayesian modeling, oriented towards linguists and psychologists. Topics to be covered: Introduction to Bayesian data analysis, Linear Modeling, Hierarchical Models. We will cover these topics within the context of an applied Bayesian workflow that includes exploratory data analysis, model fitting, and model checking using simulation. Participants are expected to be familiar with R, and must have some experience in data analysis, particularly with the R library lme4.Course Materials Previous year's course web page: all materials (videos etc.) from the previous year are available here.
Textbook: here. We will work through the first six chapters.
2. Advanced Bayesian data analysis (maximum 30 participants). Taught by Bruno Nicenboim, assisted by Himanshu Yadav
This course assumes that participants have some experience in Bayesian modeling already using brms and want to transition to Stan to learn more advanced methods and start building simple computational cognitive models. Participants should have worked through or be familiar with the material in the first five chapters of our book draft: Introduction to Bayesian Data Analysis for Cognitive Science. In this course, we will cover Parts III to V of our book draft: model comparison using Bayes factors and k-fold cross validation, introduction and relatively advanced models with Stan, and simple computational cognitive models.
Course Materials
Textbook here. We
will start from Part III of the book (Advanced models with Stan).
Participants are expected to be familiar with the first five chapters.
3. Foundational methods in frequentist statistics (maximum 30 participants). Taught by Audrey Buerki, Daniel Schad, and João Veríssimo.
Participants will be expected to have used linear mixed models before, to the level of the textbook by Winter (2019, Statistics for Linguists), and want to acquire a deeper knowledge of frequentist foundations, and understand the linear mixed modeling framework more deeply. Participants are also expected to have fit multiple regressions. We will cover model selection, contrast coding, with a heavy emphasis on simulations to compute power and to understand what the model implies. We will work on (at least some of) the participants' own datasets. This course is not appropriate for researchers new to R or to frequentist statistics.
Course Materials
Textbook draft here.
4. Advanced methods in frequentist statistics with Julia (maximum 30 participants). Taught by Reinhold Kliegl, Phillip Alday, Julius Krumbiegel, and Doug Bates.
Applicants must have experience with linear mixed models and be interested in learning how to carry out such analyses with the Julia-based MixedModels.jl package) (i.e., the analogue of the R-based lme4 package). MixedModels.jl has some significant advantages. Some of them are: (a) new and more efficient computational implementation, (b) speed — needed for, e.g., complex designs and power simulations, (c) more flexibility for selection of parsimonious mixed models, and (d) more flexibility in taking into account autocorrelations or other dependencies — typical EEG-, fMRI-based time series (under development). We do not expect profound knowledge of Julia from participants; the necessary subset of knowledge will be taught on the first day of the course. We do expect a readiness to install Julia and the confidence that with some basic instruction participants will be able to adapt prepared Julia scripts for their own data or to adapt some of their own lme4-commands to the equivalent MixedModels.jl-commands. The course will be taught in a hybrid IDE. There is already the option to execute R chunks from within Julia, meaning one needs Julia primarily for execution of MixedModels.jl commands as replacement of lme4. There is also an option to call MixedModels.jl from within R and process the resulting object like an lme4-object. Thus, much of pre- and postprocessing (e.g., data simulation for complex experimental designs; visualization of partial-effect interactions or shrinkage effects) can be carried out in R.
Course Materials Github repo: here.
Applicants must have experience with linear mixed models and be interested in learning how to carry out such analyses with the Julia-based MixedModels.jl package) (i.e., the analogue of the R-based lme4 package). MixedModels.jl has some significant advantages. Some of them are: (a) new and more efficient computational implementation, (b) speed — needed for, e.g., complex designs and power simulations, (c) more flexibility for selection of parsimonious mixed models, and (d) more flexibility in taking into account autocorrelations or other dependencies — typical EEG-, fMRI-based time series (under development). We do not expect profound knowledge of Julia from participants; the necessary subset of knowledge will be taught on the first day of the course. We do expect a readiness to install Julia and the confidence that with some basic instruction participants will be able to adapt prepared Julia scripts for their own data or to adapt some of their own lme4-commands to the equivalent MixedModels.jl-commands. The course will be taught in a hybrid IDE. There is already the option to execute R chunks from within Julia, meaning one needs Julia primarily for execution of MixedModels.jl commands as replacement of lme4. There is also an option to call MixedModels.jl from within R and process the resulting object like an lme4-object. Thus, much of pre- and postprocessing (e.g., data simulation for complex experimental designs; visualization of partial-effect interactions or shrinkage effects) can be carried out in R.
Course Materials Github repo: here.
New paper in Computational Brain and Behavior: Sample size determination in Bayesian Linear Mixed Models
We've just had a paper accepted in Computational Brain and Behavior, an open access journal of the Society for Mathematical Psychology.
Even though I am not a psychologist, I feel an increasing affinity to this field compared to psycholinguistics proper. I will be submitting more of my papers to this journal and other open access journals (Glossa Psycholx, Open Mind in particular) in the future.
Some things I liked about this journal:
- A fast and well-informed, intelligent, useful set of reviews. The reviewers actually understand what they are talking about! It's refreshing to find people out there who speak my language (and I don't mean English or Hindi). Also, the reviewers signed their reviews. This doesn't usually happen.
- Free availability of the paper after publication; I didn't have to do anything to make this happen. By contrast, I don't even have copies of my own articles published in APA journals. The same goes for Elsevier journals like the Journal of Memory and Language. Either I shell out $$$ to make the paper open access, or I learn to live with the arXiv version of my paper.
- The proofing was *excellent*. By contrast, the Journal of Memory and Language adds approximately 500 mistakes into my papers every time they publish it (then we have to correct them, if we catch them at all). E.g., in this paper we had to issue a correction about a German example; this error was added by the proofer! Another surprising example of JML actually destroying our paper's formatting is this one; here, the arXiv version has better formatting than the published paper, which cost several thousand Euros!
- LaTeX is encouraged. By contrast, APA journals demand that papers be submitted in W**d.
Here is the paper itself: here, we present an approach, adapted from the work of two statisticians (Wang and Gelfand), for determining approximate sample size needed for drawing meaningful inferences using Bayes factors in hierarchical models (aka linear mixed models). The example comes from a psycholinguistic study but the method is general. Code and data are of course available online.
The pdf: https://link.springer.com/article/10.1007/s42113-021-00125-y

Thursday, February 03, 2022
EMLAR 2022 tutorial on Bayesian methods
At EMLAR 2022 I will teach two sessions that will introduce Bayesian methods. Here is the abstract for the two sessions:
EMLAR 2022: An introduction to Bayesian data analysis
Taught by Shravan Vasishth (vasishth.github.io)
Session 1. Tuesday 19 April 2022, 1-3PM (Zoom link will be provided)
Modern probabilistic programming languages like Stan (mc-stan.org)
have made Bayesian methods increasingly accessible to researchers
in linguistics and psychology. However, finding an entry point
into these methods is often difficult for researchers. In this
tutorial, I will provide an informal introduction to the
fundamental ideas behind Bayesian statistics, using examples
that illustrate applications to psycholinguistics.
I will also discuss some of the advantages of the Bayesian
approach over the standardly used frequentist paradigms:
uncertainty quantification, robust estimates through regularization,
the ability to incorporate expert and/or prior knowledge into
the data analysis, and the ability to flexibly define the
generative process and thereby to directly address the actual research
question (as opposed to a straw-man null hypothesis).
Suggestions for further reading will be provided. In this tutorial,
I presuppose that the audience is familiar with linear mixed models
(as used in R with the package lme4).
Session 2. Thursday 21 April 2022, 9:30-11:30 (Zoom link will be provided)
This session presupposed that the participant has attended
Session 1. I will show some case studies using brms and Stan
code that will demonstrate the major applications of
Bayesian methods in psycholinguistics. I will reference/use some of
the material described in this online textbook (in progress):
Tuesday, December 14, 2021
New paper in Computational Brain and Behavior: Sample size determination for Bayesian hierarchical models commonly used in psycholinguistics
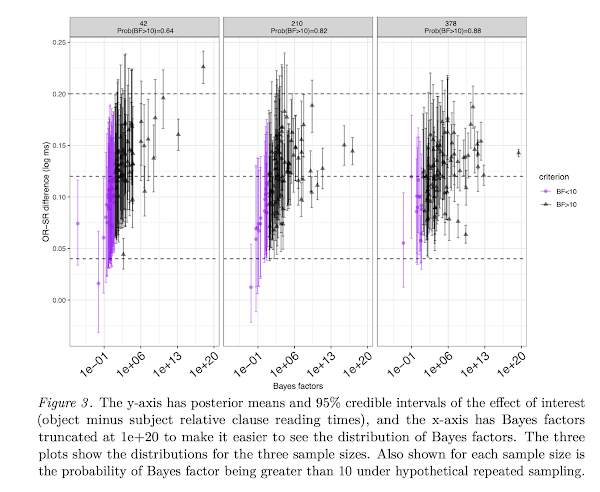
We have just had a paper accepted in the journal Computational Brain and Behavior. This is part of a special issue that responds to the following paper on linear mixed models:
van Doorn, J., Aust, F., Haaf, J.M. et al. Bayes Factors for Mixed Models. Computational Brain and Behavior (2021). https://doi.org/10.1007/s42113-021-00113-2
There are quite a few papers in that special issue, all worth reading, but I especially liked the contribution by Singmann et al: Statistics in the Service of Science: Don't let the Tail Wag the Dog (https://psyarxiv.com/kxhfu/) They make some very good points in reaction to van Doorn et al's paper.
van Doorn, J., Aust, F., Haaf, J.M. et al. Bayes Factors for Mixed Models. Computational Brain and Behavior (2021). https://doi.org/10.1007/s42113-021-00113-2
There are quite a few papers in that special issue, all worth reading, but I especially liked the contribution by Singmann et al: Statistics in the Service of Science: Don't let the Tail Wag the Dog (https://psyarxiv.com/kxhfu/) They make some very good points in reaction to van Doorn et al's paper.
Our paper:
Shravan Vasishth, Himanshu Yadav, Daniel J. Schad, and Bruno Nicenboim. Sample size determination for Bayesian hierarchical models commonly used in psycholinguistics. Computational Brain and Behavior, 2021.
Abstract: We discuss an important issue that is not directly related to the main theses of the van Doorn et al. (2021) paper, but which frequently comes up when using Bayesian linear mixed models: how to determine sample size in advance of running a study when planning a Bayes factor analysis. We adapt a simulation-based method proposed by Wang and Gelfand (2002) for a Bayes-factor based design analysis, and demonstrate how relatively complex hierarchical models can be used to determine approximate sample sizes for planning experiments.
Code and data: https://osf.io/hjgrm/
pdf: here
Abstract: We discuss an important issue that is not directly related to the main theses of the van Doorn et al. (2021) paper, but which frequently comes up when using Bayesian linear mixed models: how to determine sample size in advance of running a study when planning a Bayes factor analysis. We adapt a simulation-based method proposed by Wang and Gelfand (2002) for a Bayes-factor based design analysis, and demonstrate how relatively complex hierarchical models can be used to determine approximate sample sizes for planning experiments.
Code and data: https://osf.io/hjgrm/
pdf: here
Subscribe to:
Posts (Atom)