Himanshu Yadav ended his 3+ year stay at my lab today and will start a tenure-track assistant professorship at the Indian Institute of Technology, Kanpur in India, Department of Cognitive Science. He's the eighth professor from my lab.

Michael Betancourt, a giant in the field of Bayesian statistical modeling, once indirectly pointed out to me (in a podcast interview) that one should not try to model latent cognitive processes in reading by computing summary statistics like the mean difference between conditions and then fitting the model on those summary statistics. But that is exactly what we do in psycholinguistics. Most models (including those from my lab) evaluate model performance on summary statistics from the data (usually, a mean difference), abstracting away quite dramatically from the complex processes that resulted in those reading times and regressive eye movements.
What Michael wanted instead was a detailed process model of how the observed fixations and eye movement patterns arise. Obviously, such a model would be extremely complicated, because one would have to specify the full details of oculomotor processes and their impact on eye movements, as well as a model of language comprehension, and specify how these components interact to produce eye movements at the single trial level. This kind of model will quickly become computationally intractable if one tries to estimate the model parameters using data. So that's a major barrier to building such a model.
Interestingly, both eye movement control models and models of sentence comprehension exist. But these live in parallel universes. Psychologists have almost always focused on eye movement control, ignoring the impact of sentence comprehension processes (I once heard a talk by a psychologist who publicly called out psycholinguists, labeling them as "crazy" for studying language processing in reading :). Similarly, most psycholinguists just ignore the lower-level processes unfolding in reading, and just assume that language processing events are responsible for differences in fixation durations or in left-ward eye movements (regressions). The most that psycholinguists like me are willing to do is add word frequency etc. as a co-predictor to reading time or other dependent measures when investigating reading. But in most cases even that would go too far :).
What is missing is a model that brings these two lines of work into one integrated reading model that co-determines where we move our eyes to and for how long.
Max Rabe, who is wrapping up his PhD work in psychology at Potsdam in Germany, demonstrates how this could be done: he takes a fully specified model of eye movement control in reading (SWIFT) and integrates into it linguistic dependency completion processes, following the principles of the cognitive architecture ACT-R. A key achievement is that the activation of a word being read is co-determined by both oculomotor processes as specified in SWIFT, and cue-based retrieval processes as specified in the activation-based model of retrieval. A key achievement is to show how regressive eye movements are triggered when sentence processing difficulty (here, similarity-based interference) arises during reading.
What made the model fitting possible was Bayesian parameter estimation: Max Rabe shows in an earlier (2021) Psychological Review paper (preprint here) how parameter estimation can be carried out in complex models where the likelihood function may not be easy to work out.
Download the paper from arXiv.
Here is an important paper for the field of psycholionguistics that just came out in JML. It is led by Dr. Anna Laurinavichyute and was commissioned by the editor of JML (Prof. Kathy Rastle).
Download here: https://doi.org/10.1016/j.jml.2022.104332
TRIGGER WARNING: These simulations might fundamentally shake your belief system. USE WITH CARE.
In a recently accepted paper in the open access journal Quantitative Methods for Psychology that Daniel Schad led, we discuss how, using Bayes' rule, one can explore the change in the probability of a null hypothesis being true (call it theta) when you get a significant effect. The paper, which was inspired by a short comment in McElreath's book (first edition), shows that theta does not necessarily change much even if you get a significant result. The probability theta can change dramatically under certain conditions, but those conditions are either so stringent or so trivial that it renders many of the significance-based conclusions in psychology and psycholinguistics questionable at the very least.
You can do your own simulations, under assumptions that you consider more appropriate for your own research problem, using this shiny app (below), or play with the source code: here.
Here's an important new paper led by Dr. Anna Laurinavichyute on the reproducibility of published analyses. This paper by commissioned by the editor in chief of the Journal of Memory and Language, Kathy Rastle.
Title: Share the code, not just the data: A case study of the reproducibility of JML articles published under the open data policy
Abstract:
In 2019 the Journal of Memory and Language instituted an open data and code policy; this policy requires that, as a rule, code and data be released at the latest upon publication. How effective is this policy? We compared 59 papers published before, and 59 papers published after, the policy took effect. After the policy was in place, the rate of data sharing increased by more than 50%. We further looked at whether papers published under the open data policy were reproducible, in the sense that the published results should be possible to regenerate given the data, and given the code, when code was provided. For 8 out of the 59 papers, data sets were inaccessible. The reproducibility rate ranged from 34% to 56%, depending on the reproducibility criteria. The strongest predictor of whether an attempt to reproduce would be successful is the presence of the analysis code: it increases the probability of reproducing reported results by almost 40%. We propose two simple steps that can increase the reproducibility of published papers: share the analysis code, and attempt to reproduce one’s own analysis using only the shared materials.
PDF: here.
I will be teaching an in-person course on linear mixed modeling at the summer school at Ghent (below) August 2022.
The summer school home page: https://www.mils.ugent.be/
1. 2.5 day course: Introduction to linear mixed modelling for linguists
When and where: August 18, 19, 20, 2022 in Ghent.
Prerequisites and target audience
The target audience is graduate students in linguistics.
I assume familiarity with graphical descriptive summaries of data of the type
encountered in linguistics; the most important theoretical distributions
(normal, t, binomial, chi-squared); description of univariate and bivariate data
(mean, variance, standard deviation, correlation, cross-tabulations);
graphical presentation of univariate and bivariate/multivariate data
(bar chart, histogram, boxplot, qq-plot, etc.);
point estimators and confidence intervals for population averages
with normal data or large samples;
null hypothesis significance testing;
t-test, Chi-square test, simple linear regression.
A basic knowledge of R is assumed.
Curriculum:
I will cover some important ideas relating to linear mixed models
and how they can be used in linguistics research. I will loosely follow
my textbook draft: https://vasishth.github.io/Freq_CogSci/
Topics to be covered:
- Linear mixed models: basic theory and applications
- Contrast coding
- Generalized Linear Mixed Models (binomial link)
- Using simulation for power analysis and for understanding one’s model
2. Keynote lecture
Using Bayesian Data Analysis in Language Research
Shravan VasishthNew paper (under review):
Title: Some right ways to analyze (psycho)linguistic data
Abstract:
Much has been written on the abuse and misuse of statistical methods, including p-values, statistical significance, etc. I present some of the best practices in statistics using a running example data analysis. Focusing primarily on frequentist and Bayesian linear mixed models, I illustrate some defensible ways in which statistical inference—specifically, hypothesis testing using Bayes factors vs. estimation or uncertainty quantification—can be carried out. The key is to not overstate the evidence and to not expect too much from statistics. Along the way, I demonstrate some powerful ideas, the most important ones being using simulation to understand the design properties of one’s experiment before running it, visualizing data before carrying out a formal analysis, and simulating data from the fitted model to understand the model’s behavior.
PDF: https://psyarxiv.com/y54va/
The application form closes April 1, 2022. We will announce the decisions on or around April 15, 2022.
Course fee: There is no fee because the summer school is funded by the Collaborative Research Center (Sonderforschungsbereich 1287). However, we will charge 40 Euros to cover costs for coffee and snacks during the breaks and social hours. And participants will have to pay for their own accommodation.
For details, see: https://vasishth.github.io/
Curriculum:
1. Introduction to Bayesian data analysis (maximum 30 participants). Taught by Shravan Vasishth, assisted by Anna Laurinavichyute, and Paula Lissón
This course is an introduction to Bayesian modeling, oriented towards linguists and psychologists. Topics to be covered: Introduction to Bayesian data analysis, Linear Modeling, Hierarchical Models. We will cover these topics within the context of an applied Bayesian workflow that includes exploratory data analysis, model fitting, and model checking using simulation. Participants are expected to be familiar with R, and must have some experience in data analysis, particularly with the R library lme4.We've just had a paper accepted in Computational Brain and Behavior, an open access journal of the Society for Mathematical Psychology.
Even though I am not a psychologist, I feel an increasing affinity to this field compared to psycholinguistics proper. I will be submitting more of my papers to this journal and other open access journals (Glossa Psycholx, Open Mind in particular) in the future.
Some things I liked about this journal:
- A fast and well-informed, intelligent, useful set of reviews. The reviewers actually understand what they are talking about! It's refreshing to find people out there who speak my language (and I don't mean English or Hindi). Also, the reviewers signed their reviews. This doesn't usually happen.
- Free availability of the paper after publication; I didn't have to do anything to make this happen. By contrast, I don't even have copies of my own articles published in APA journals. The same goes for Elsevier journals like the Journal of Memory and Language. Either I shell out $$$ to make the paper open access, or I learn to live with the arXiv version of my paper.
- The proofing was *excellent*. By contrast, the Journal of Memory and Language adds approximately 500 mistakes into my papers every time they publish it (then we have to correct them, if we catch them at all). E.g., in this paper we had to issue a correction about a German example; this error was added by the proofer! Another surprising example of JML actually destroying our paper's formatting is this one; here, the arXiv version has better formatting than the published paper, which cost several thousand Euros!
- LaTeX is encouraged. By contrast, APA journals demand that papers be submitted in W**d.
Here is the paper itself: here, we present an approach, adapted from the work of two statisticians (Wang and Gelfand), for determining approximate sample size needed for drawing meaningful inferences using Bayes factors in hierarchical models (aka linear mixed models). The example comes from a psycholinguistic study but the method is general. Code and data are of course available online.
The pdf: https://link.springer.com/article/10.1007/s42113-021-00125-y

At EMLAR 2022 I will teach two sessions that will introduce Bayesian methods. Here is the abstract for the two sessions:
EMLAR 2022: An introduction to Bayesian data analysis
Taught by Shravan Vasishth (vasishth.github.io)
Session 1. Tuesday 19 April 2022, 1-3PM (Zoom link will be provided)
Modern probabilistic programming languages like Stan (mc-stan.org)
have made Bayesian methods increasingly accessible to researchers
in linguistics and psychology. However, finding an entry point
into these methods is often difficult for researchers. In this
tutorial, I will provide an informal introduction to the
fundamental ideas behind Bayesian statistics, using examples
that illustrate applications to psycholinguistics.
I will also discuss some of the advantages of the Bayesian
approach over the standardly used frequentist paradigms:
uncertainty quantification, robust estimates through regularization,
the ability to incorporate expert and/or prior knowledge into
the data analysis, and the ability to flexibly define the
generative process and thereby to directly address the actual research
question (as opposed to a straw-man null hypothesis).
Suggestions for further reading will be provided. In this tutorial,
I presuppose that the audience is familiar with linear mixed models
(as used in R with the package lme4).
Session 2. Thursday 21 April 2022, 9:30-11:30 (Zoom link will be provided)
This session presupposed that the participant has attended
Session 1. I will show some case studies using brms and Stan
code that will demonstrate the major applications of
Bayesian methods in psycholinguistics. I will reference/use some of
the material described in this online textbook (in progress):
Here's a new opinion paper in Trends in Cognitive Sciences, by Ralf Engbert, Max Rabe, et al.
Link to paper: here

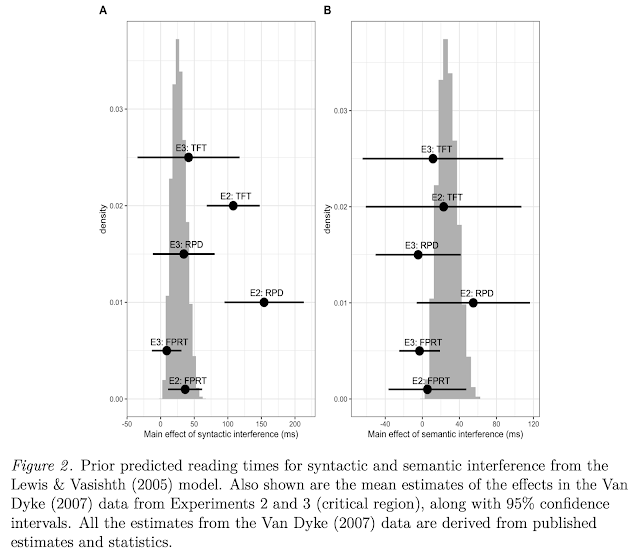

A long-standing debate in the sentence processing literature concerns the time course of syntactic and semantic information in online sentence comprehension. The default assumption in cue-based models of parsing is that syntactic and semantic retrieval cues simultaneously guide dependency resolution. When retrieval cues match multiple items in memory, this leads to similarity-based interference. Both semantic and syntactic interference have been shown to occur in English. However, the relative timing of syntactic vs. semantic interference remains unclear. In this first-ever cross-linguistic investigation of the time course of syntactic vs. semantic interference, the data from two eye-tracking reading experiments (English and German) suggest that the two types of interference can in principle arise simultaneously during retrieval. However, the data also indicate that semantic cues may be evaluated with a small timing lag in German compared to English. This suggests that there may be cross-linguistic variation in how syntactic and semantic cues are used to resolve linguistic dependencies in real-time.
Download pdf from here: https://psyarxiv.com/ua9yv


Here's an interesting and important new paper led by the inimitable Dario Paape:
Title: When nothing goes right, go left: A large-scale evaluation of bidirectional self-paced reading
Download from: here.
Abstract:
In two web-based experiments, we evaluated the bidirectional self-paced reading (BSPR) paradigm recently proposed by Paape and Vasishth (2021). We used four sentence types: NP/Z garden-path sentences, RRC garden-path sentences, sentences containing inconsistent discourse continuations, and sentences containing reflexive anaphors with feature-matching but grammatically unavailable antecedents. Our results show that regressions in BSPR are associated with a decrease in positive acceptability judgments. Across all sentence types, we observed online reading patterns that are consistent with the existing eye-tracking literature. NP/Z but not RRC garden-path sentences also showed some indication of selective rereading, as predicted by the selective reanalysis hypothesis of Frazier and Rayner (1982). However, selective rereading was associated with decreased rather than increased sentence acceptability, which is not in line with the selective reanalysis hypothesis. We discuss the implications regarding the connection between selective rereading and conscious awareness, and for the use of BSPR in general.
New paper by Anna Laurinavichyute and me:
The (ir)reproducibility of published analyses: A case study of 57 JML articles published between 2019 and 2021
Download from: https://psyarxiv.com/hf297/

