These recordings are part of a set of videos that are available from the free four-week online course Introduction to Bayesian Data Analysis, taught over the openhpi.de portal.
Showing posts with label Stan. Show all posts
Showing posts with label Stan. Show all posts
Monday, January 30, 2023
Tuesday, October 04, 2022
Applications open: The Seventh Summer School on Statistical Methods for Linguistics and Psychology, 11-15 September 2023
Applications are open (till 1st April 2023( for the seventh summer school on statistical methods for linguistics and psychology, to be held in Potsdam, Germany.
Summer school website: https://vasishth.github.io/smlp2023/
Some of the highlights:
1. Four parallel courses on frequentist and Bayesian methods (introductory/intermediate and advanced)
2. A special short course on Bayesian meta-analysis by Dr. Robert Grant of bayescamp.
3. You can also do this free, completely online four-week course on Introduction to Bayesian Data Analysis (starts Jan 2023): https://open.hpi.de/courses/bayesian-statistics2023
Thursday, September 08, 2022

Friday, May 27, 2022
Summer School “Methods in Language Sciences” (16-20 August 2022, Ghent, Belgium): Registrations open
I was asked to advertise this summer school (I will be teaching a 2.5 day course on linear mixed modeling, and will give a keynote lecture on the use of Bayesian methods in linguistics/psychology). The text below is from the organizers.
Summer School “Methods in Language Sciences” 2022:
Registrations are open
Top quality research requires outstanding methodological skills. That is why the Department
of Linguistics and the Department of Translation, Interpreting and Communication of Ghent
University will jointly organize the (second edition of the) Summer School “Methods in
Language Sciences” on 16-20 August 2022.
This Summer School is targeted at both junior and senior researchers and offers nine multi-
day modules on various topics, ranging from quantitative to qualitative methods and
covering introductory and advanced statistical analysis, Natural Language Processing
(NLP), eye-tracking, survey design, ethnographic methods, as well as specific tools such
as PRAAT and ELAN. In 2022 we have a new module on Linear Mixed Models. All lecturers
are internationally recognized experts with a strong research and teaching background.
Because the modules will partly be held in parallel sessions, participants have to choose one
or two modules to follow (see the Programme for details). No prerequisite knowledge or
experience is required, except for Modules 2 and 9, which deal with advanced statistical data
analysis.
We are proud to welcome two keynote speakers at this year’s summer school: Shravan
Vasishth and Crispin Thurlow, who both also act as lecturers.
This is your opportunity to take your methodological skills for research in (applied)
linguistics, translation or interpreting studies to the next level. We are looking forward to
meeting you in Ghent!
Wednesday, March 23, 2022
Summer School on Statistical Methods for Linguistics and Psychology, Sept. 12-16, 2022 (applications close April 1)
The Sixth Summer
School on Statistical Methods for Linguistics and Psychology will be
held in Potsdam, Germany, September 12-16, 2022. Like the previous
editions of the summer school, this edition will have two frequentist
and two Bayesian streams. Currently, this summer school is being planned
as an in-person event.
The application form closes April 1, 2022. We will announce the decisions on or around April 15, 2022.
Course fee: There is no fee because the summer school is funded by the Collaborative Research Center (Sonderforschungsbereich 1287). However, we will charge 40 Euros to cover costs for coffee and snacks during the breaks and social hours. And participants will have to pay for their own accommodation.
For details, see: https://vasishth.github.io/
Curriculum:
1. Introduction to Bayesian data analysis (maximum 30 participants). Taught by Shravan Vasishth, assisted by Anna Laurinavichyute, and Paula Lissón
This course is an introduction to Bayesian modeling, oriented towards linguists and psychologists. Topics to be covered: Introduction to Bayesian data analysis, Linear Modeling, Hierarchical Models. We will cover these topics within the context of an applied Bayesian workflow that includes exploratory data analysis, model fitting, and model checking using simulation. Participants are expected to be familiar with R, and must have some experience in data analysis, particularly with the R library lme4.Course Materials Previous year's course web page: all materials (videos etc.) from the previous year are available here.
Textbook: here. We will work through the first six chapters.
2. Advanced Bayesian data analysis (maximum 30 participants). Taught by Bruno Nicenboim, assisted by Himanshu Yadav
This course assumes that participants have some experience in Bayesian modeling already using brms and want to transition to Stan to learn more advanced methods and start building simple computational cognitive models. Participants should have worked through or be familiar with the material in the first five chapters of our book draft: Introduction to Bayesian Data Analysis for Cognitive Science. In this course, we will cover Parts III to V of our book draft: model comparison using Bayes factors and k-fold cross validation, introduction and relatively advanced models with Stan, and simple computational cognitive models.
Course Materials
Textbook here. We
will start from Part III of the book (Advanced models with Stan).
Participants are expected to be familiar with the first five chapters.
3. Foundational methods in frequentist statistics (maximum 30 participants). Taught by Audrey Buerki, Daniel Schad, and João Veríssimo.
Participants will be expected to have used linear mixed models before, to the level of the textbook by Winter (2019, Statistics for Linguists), and want to acquire a deeper knowledge of frequentist foundations, and understand the linear mixed modeling framework more deeply. Participants are also expected to have fit multiple regressions. We will cover model selection, contrast coding, with a heavy emphasis on simulations to compute power and to understand what the model implies. We will work on (at least some of) the participants' own datasets. This course is not appropriate for researchers new to R or to frequentist statistics.
Course Materials
Textbook draft here.
4. Advanced methods in frequentist statistics with Julia (maximum 30 participants). Taught by Reinhold Kliegl, Phillip Alday, Julius Krumbiegel, and Doug Bates.
Applicants must have experience with linear mixed models and be interested in learning how to carry out such analyses with the Julia-based MixedModels.jl package) (i.e., the analogue of the R-based lme4 package). MixedModels.jl has some significant advantages. Some of them are: (a) new and more efficient computational implementation, (b) speed — needed for, e.g., complex designs and power simulations, (c) more flexibility for selection of parsimonious mixed models, and (d) more flexibility in taking into account autocorrelations or other dependencies — typical EEG-, fMRI-based time series (under development). We do not expect profound knowledge of Julia from participants; the necessary subset of knowledge will be taught on the first day of the course. We do expect a readiness to install Julia and the confidence that with some basic instruction participants will be able to adapt prepared Julia scripts for their own data or to adapt some of their own lme4-commands to the equivalent MixedModels.jl-commands. The course will be taught in a hybrid IDE. There is already the option to execute R chunks from within Julia, meaning one needs Julia primarily for execution of MixedModels.jl commands as replacement of lme4. There is also an option to call MixedModels.jl from within R and process the resulting object like an lme4-object. Thus, much of pre- and postprocessing (e.g., data simulation for complex experimental designs; visualization of partial-effect interactions or shrinkage effects) can be carried out in R.
Course Materials Github repo: here.
Applicants must have experience with linear mixed models and be interested in learning how to carry out such analyses with the Julia-based MixedModels.jl package) (i.e., the analogue of the R-based lme4 package). MixedModels.jl has some significant advantages. Some of them are: (a) new and more efficient computational implementation, (b) speed — needed for, e.g., complex designs and power simulations, (c) more flexibility for selection of parsimonious mixed models, and (d) more flexibility in taking into account autocorrelations or other dependencies — typical EEG-, fMRI-based time series (under development). We do not expect profound knowledge of Julia from participants; the necessary subset of knowledge will be taught on the first day of the course. We do expect a readiness to install Julia and the confidence that with some basic instruction participants will be able to adapt prepared Julia scripts for their own data or to adapt some of their own lme4-commands to the equivalent MixedModels.jl-commands. The course will be taught in a hybrid IDE. There is already the option to execute R chunks from within Julia, meaning one needs Julia primarily for execution of MixedModels.jl commands as replacement of lme4. There is also an option to call MixedModels.jl from within R and process the resulting object like an lme4-object. Thus, much of pre- and postprocessing (e.g., data simulation for complex experimental designs; visualization of partial-effect interactions or shrinkage effects) can be carried out in R.
Course Materials Github repo: here.
New paper in Computational Brain and Behavior: Sample size determination in Bayesian Linear Mixed Models
We've just had a paper accepted in Computational Brain and Behavior, an open access journal of the Society for Mathematical Psychology.
Even though I am not a psychologist, I feel an increasing affinity to this field compared to psycholinguistics proper. I will be submitting more of my papers to this journal and other open access journals (Glossa Psycholx, Open Mind in particular) in the future.
Some things I liked about this journal:
- A fast and well-informed, intelligent, useful set of reviews. The reviewers actually understand what they are talking about! It's refreshing to find people out there who speak my language (and I don't mean English or Hindi). Also, the reviewers signed their reviews. This doesn't usually happen.
- Free availability of the paper after publication; I didn't have to do anything to make this happen. By contrast, I don't even have copies of my own articles published in APA journals. The same goes for Elsevier journals like the Journal of Memory and Language. Either I shell out $$$ to make the paper open access, or I learn to live with the arXiv version of my paper.
- The proofing was *excellent*. By contrast, the Journal of Memory and Language adds approximately 500 mistakes into my papers every time they publish it (then we have to correct them, if we catch them at all). E.g., in this paper we had to issue a correction about a German example; this error was added by the proofer! Another surprising example of JML actually destroying our paper's formatting is this one; here, the arXiv version has better formatting than the published paper, which cost several thousand Euros!
- LaTeX is encouraged. By contrast, APA journals demand that papers be submitted in W**d.
Here is the paper itself: here, we present an approach, adapted from the work of two statisticians (Wang and Gelfand), for determining approximate sample size needed for drawing meaningful inferences using Bayes factors in hierarchical models (aka linear mixed models). The example comes from a psycholinguistic study but the method is general. Code and data are of course available online.
The pdf: https://link.springer.com/article/10.1007/s42113-021-00125-y

Thursday, February 03, 2022
EMLAR 2022 tutorial on Bayesian methods
At EMLAR 2022 I will teach two sessions that will introduce Bayesian methods. Here is the abstract for the two sessions:
EMLAR 2022: An introduction to Bayesian data analysis
Taught by Shravan Vasishth (vasishth.github.io)
Session 1. Tuesday 19 April 2022, 1-3PM (Zoom link will be provided)
Modern probabilistic programming languages like Stan (mc-stan.org)
have made Bayesian methods increasingly accessible to researchers
in linguistics and psychology. However, finding an entry point
into these methods is often difficult for researchers. In this
tutorial, I will provide an informal introduction to the
fundamental ideas behind Bayesian statistics, using examples
that illustrate applications to psycholinguistics.
I will also discuss some of the advantages of the Bayesian
approach over the standardly used frequentist paradigms:
uncertainty quantification, robust estimates through regularization,
the ability to incorporate expert and/or prior knowledge into
the data analysis, and the ability to flexibly define the
generative process and thereby to directly address the actual research
question (as opposed to a straw-man null hypothesis).
Suggestions for further reading will be provided. In this tutorial,
I presuppose that the audience is familiar with linear mixed models
(as used in R with the package lme4).
Session 2. Thursday 21 April 2022, 9:30-11:30 (Zoom link will be provided)
This session presupposed that the participant has attended
Session 1. I will show some case studies using brms and Stan
code that will demonstrate the major applications of
Bayesian methods in psycholinguistics. I will reference/use some of
the material described in this online textbook (in progress):
Tuesday, December 14, 2021
New paper in Computational Brain and Behavior: Sample size determination for Bayesian hierarchical models commonly used in psycholinguistics
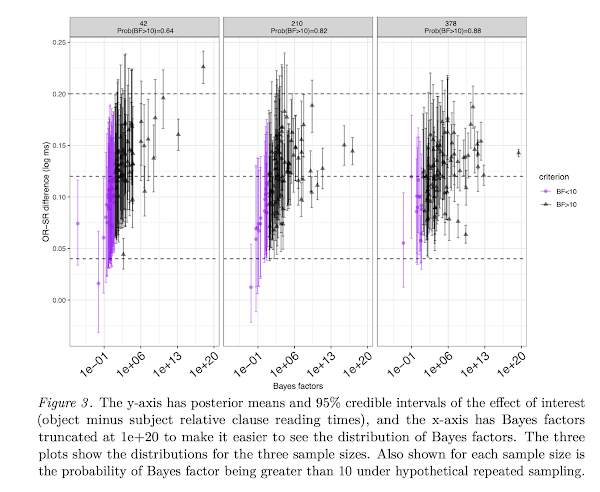
We have just had a paper accepted in the journal Computational Brain and Behavior. This is part of a special issue that responds to the following paper on linear mixed models:
van Doorn, J., Aust, F., Haaf, J.M. et al. Bayes Factors for Mixed Models. Computational Brain and Behavior (2021). https://doi.org/10.1007/s42113-021-00113-2
There are quite a few papers in that special issue, all worth reading, but I especially liked the contribution by Singmann et al: Statistics in the Service of Science: Don't let the Tail Wag the Dog (https://psyarxiv.com/kxhfu/) They make some very good points in reaction to van Doorn et al's paper.
van Doorn, J., Aust, F., Haaf, J.M. et al. Bayes Factors for Mixed Models. Computational Brain and Behavior (2021). https://doi.org/10.1007/s42113-021-00113-2
There are quite a few papers in that special issue, all worth reading, but I especially liked the contribution by Singmann et al: Statistics in the Service of Science: Don't let the Tail Wag the Dog (https://psyarxiv.com/kxhfu/) They make some very good points in reaction to van Doorn et al's paper.
Our paper:
Shravan Vasishth, Himanshu Yadav, Daniel J. Schad, and Bruno Nicenboim. Sample size determination for Bayesian hierarchical models commonly used in psycholinguistics. Computational Brain and Behavior, 2021.
Abstract: We discuss an important issue that is not directly related to the main theses of the van Doorn et al. (2021) paper, but which frequently comes up when using Bayesian linear mixed models: how to determine sample size in advance of running a study when planning a Bayes factor analysis. We adapt a simulation-based method proposed by Wang and Gelfand (2002) for a Bayes-factor based design analysis, and demonstrate how relatively complex hierarchical models can be used to determine approximate sample sizes for planning experiments.
Code and data: https://osf.io/hjgrm/
pdf: here
Abstract: We discuss an important issue that is not directly related to the main theses of the van Doorn et al. (2021) paper, but which frequently comes up when using Bayesian linear mixed models: how to determine sample size in advance of running a study when planning a Bayes factor analysis. We adapt a simulation-based method proposed by Wang and Gelfand (2002) for a Bayes-factor based design analysis, and demonstrate how relatively complex hierarchical models can be used to determine approximate sample sizes for planning experiments.
Code and data: https://osf.io/hjgrm/
pdf: here
Monday, December 06, 2021
New paper: Similarity-based interference in sentence comprehension in aphasia: A computational evaluation of two models of cue-based retrieval.

Title: Similarity-based interference in sentence comprehension in aphasia: A computational evaluation of two models of cue-based retrieval.
Abstract: Sentence comprehension requires the listener to link incoming words with short-term memory representations in order to build linguistic dependencies. The cue-based retrieval theory of sentence processing predicts that the retrieval of these memory representations is affected by similarity-based interference. We present the first large-scale computational evaluation of interference effects in two models of sentence processing – the activation-based model, and a modification of the direct-access model – in individuals with aphasia (IWA) and control participants in German. The parameters of the models are linked to prominent theories of processing deficits in aphasia, and the models are tested against two linguistic constructions in German: Pronoun resolution and relative clauses. The data come from a visual-world eye-tracking experiment combined with a sentence-picture matching task. The results show that both control participants and IWA are susceptible to retrieval interference, and that a combination of theoretical explanations (intermittent deficiencies, slow syntax, and resource reduction) can explain IWA’s deficits in sentence processing. Model comparisons reveal that both models have a similar predictive performance in pronoun resolution, but the activation-based model outperforms the direct-access model in relative clauses.
Download: here. Paula also has another paper modeling English data from unimpaired controls and individuals in aphasia, in Cognitive Science.
Friday, November 12, 2021
Book: Sentence comprehension as a cognitive process: A computational approach (Vasishth and Engelmann)
My book with Felix Engelmann has just been published. It puts together in one place 20 years of research on retrieval models, carried out by my students, colleagues, and myself.

Friday, September 17, 2021
Applications are open: 2022 summer school on stats methods for ling and psych
Applications are now open for the sixth SMLP summer school, to be held in person (hopefully) in the Griebnitzsee campus of the University of Potsdam, Germany, 12-16 Sept 2022.
Apply here: https://vasishth.github.io/smlp2022/
Tuesday, April 20, 2021
New paper in Cognitive Science (open access): A Computational Evaluation of Two Models of Retrieval Processes in Sentence Processing in Aphasia
An exciting new paper by my PhD student Paula Lissón
Download from here: https://onlinelibrary.wiley.com/doi/10.1111/cogs.12956
Code and data: https://osf.io/kdjqz/
Title: A Computational Evaluation of Two Models of Retrieval Processes in Sentence Processing in Aphasia
Authors: Paula Lissón, Dorothea Pregla, Bruno Nicenboim, Dario Paape, Mick L. van het Nederend, Frank Burchert, Nicole Stadie, David Caplan, Shravan Vasishth
Abstract:
Can sentence comprehension impairments in aphasia be explained by difficulties arising from dependency completion processes in parsing? Two distinct models of dependency completion difficulty are investigated, the Lewis and Vasishth (2005) activation‐based model and the direct‐access model (DA; McElree, 2000). These models' predictive performance is compared using data from individuals with aphasia (IWAs) and control participants. The data are from a self‐paced listening task involving subject and object relative clauses. The relative predictive performance of the models is evaluated using k‐fold cross‐validation. For both IWAs and controls, the activation‐based model furnishes a somewhat better quantitative fit to the data than the DA model. Model comparisons using Bayes factors show that, assuming an activation‐based model, intermittent deficiencies may be the best explanation for the cause of impairments in IWAs, although slowed syntax and lexical delayed access may also play a role. This is the first computational evaluation of different models of dependency completion using data from impaired and unimpaired individuals. This evaluation develops a systematic approach that can be used to quantitatively compare the predictions of competing models of language processing.
Wednesday, March 17, 2021
New paper: Workflow Techniques for the Robust Use of Bayes Factors
Workflow Techniques for the Robust Use of Bayes Factors
Download from: https://arxiv.org/abs/2103.08744
Inferences about hypotheses are ubiquitous in the cognitive sciences. Bayes factors provide one general way to compare different hypotheses by their compatibility with the observed data. Those quantifications can then also be used to choose between hypotheses. While Bayes factors provide an immediate approach to hypothesis testing, they are highly sensitive to details of the data/model assumptions. Moreover it's not clear how straightforwardly this approach can be implemented in practice, and in particular how sensitive it is to the details of the computational implementation. Here, we investigate these questions for Bayes factor analyses in the cognitive sciences. We explain the statistics underlying Bayes factors as a tool for Bayesian inferences and discuss that utility functions are needed for principled decisions on hypotheses. Next, we study how Bayes factors misbehave under different conditions. This includes a study of errors in the estimation of Bayes factors. Importantly, it is unknown whether Bayes factor estimates based on bridge sampling are unbiased for complex analyses. We are the first to use simulation-based calibration as a tool to test the accuracy of Bayes factor estimates. Moreover, we study how stable Bayes factors are against different MCMC draws. We moreover study how Bayes factors depend on variation in the data. We also look at variability of decisions based on Bayes factors and how to optimize decisions using a utility function. We outline a Bayes factor workflow that researchers can use to study whether Bayes factors are robust for their individual analysis, and we illustrate this workflow using an example from the cognitive sciences. We hope that this study will provide a workflow to test the strengths and limitations of Bayes factors as a way to quantify evidence in support of scientific hypotheses. Reproducible code is available from this https URL.
Also see this interesting twitter thread on this paper by Michael Betancourt:
I believe this paper was initiated towards the end of drafting the Bayesian workflow in cognitive science paper with Daniel and @ShravanVasishth when I mentioned that many of the workflow ideas could be generalized to Bayes factor implementations with a little bit of work.
— \mathfrak{Michael "Shapes Dude" Betancourt} (@betanalpha) March 17, 2021
Saturday, January 16, 2021
Applications are open for the fifth summer school in statistical methods for linguistics and psychology (SMLP)
The annual summer school, now in its fifth edition, will happen 6-10 Sept 2021, and will be conducted virtually over zoom. The summer school is free and is funded by the DFG through SFB 1287.
Instructors: Doug Bates, Reinhold Kliegl, Phillip Alday, Bruno Nicenboim, Daniel Schad, Anna Laurinavichyute, Paula Lisson, Audrey Buerki, Shravan Vasishth.
There will be four streams running in parallel: introductory and advances courses on frequentist and Bayesian statistics. Details, including how to apply, are here.
Instructors: Doug Bates, Reinhold Kliegl, Phillip Alday, Bruno Nicenboim, Daniel Schad, Anna Laurinavichyute, Paula Lisson, Audrey Buerki, Shravan Vasishth.
There will be four streams running in parallel: introductory and advances courses on frequentist and Bayesian statistics. Details, including how to apply, are here.
Thursday, November 12, 2020
New paper: A computational evaluation of two models of retrieval processes in sentence processing in aphasia
Here is another important paper from my lab, led by my PhD student Paula Lissón, with a long list of co-authors.
This paper, which also depends heavily on the amazing capabilities of Stan, investigates the quantitative predictions of two competing models of retrieval processes, the cue-based retrieval model of Lewis and Vasishth, and the direct-access model of McElree. We have done such an investigation before, in a very exciting paper by Bruno Nicenboim, using self-paced reading data from a German number interference experiment.
What is interesting about this new paper by Paula is that the data come from individuals with aphasia and control participants. Such data is extremely difficult to collect, and as a result many papers report experimental results from a handful of people with aphasia, sometimes as few as 7 people. This paper has much more data, thanks to the hard work of David Caplan.
The big achievements of this paper are that it provides a principled approach to comparing the two competing models' predictions, and it derives testable predictions (which we are about to evaluate with new data from German individuals with aphasia---watch this space). As is always the case in psycholinguistics, even with this relatively large data-set, there just isn't enough data to draw unequivocal inferences. Our policy in my lab is to be upfront about the ambiguities inherent in the inferences. This kind of ambiguous conclusion tends to upset reviewers, because they expect (rather, demand) big-news results. But big news is, more often than not, just illusions of certainty, noise that looks like a signal (see some of my recent papers in the Journal of Memory and Language). We could easily have over-dramatized the paper and dressed it up to say way more than is warranted by the analyses. Our goal here was to tell the story with all its uncertainties laid bare. The more papers one can put out there that make more measured claims, with all the limitations laid out openly, the easier it will be for reviewers (and editors!) to learn to accept that one can learn something important from a modeling exercise without necessarily obtaining a decisive result.
Download the paper from here: https://psyarxiv.com/r7dn5
A computational evaluation of two models of retrieval processes in sentence processing in aphasia
Abstract:
Can sentence comprehension impairments in aphasia be explained by
difficulties arising from dependency completion processes in parsing?
Two distinct models of dependency
completion difficulty are investigated, the Lewis and Vasishth (2005)
activation-based model, and the direct-access model (McElree, 2000).
These models’ predictive performance is compared using data from
individuals with aphasia (IWAs) and control participants. The data are
from a self-paced listening task involving subject and object relative
clauses. The relative predictive performance of the models is evaluated
using k-fold cross validation. For both IWAs and controls, the
activation model furnishes a somewhat better quantitative
fit to the data than the direct-access model. Model comparison using
Bayes factors shows that, assuming an activation-based model,
intermittent deficiencies may be the best explanation for the cause of
impairments in IWAs. This is the first computational evaluation of
different models of dependency completion using data from impaired and
unimpaired individuals. This evaluation develops a systematic approach
that can be used to quantitatively compare the predictions of competing
models of language processing.
Wednesday, November 11, 2020
New paper: Modeling misretrieval and feature substitution in agreement attraction: A computational evaluation
This is an important new paper from our lab, led by Dario Paape, and with Serine Avetisyan, Sol Lago, and myself as co-authors.
One thing that this paper accomplishes is that it showcases the incredible expressive power of Stan, a probabilistic programming language developed by Andrew Gelman and colleagues at Columbia for Bayesian modeling. Stan allows us to implement relatively complex process models of sentence processing and test their performance against data. Paape et al show how we can quantitatively evaluate the predictions of different competing models. There are plenty of papers out there that test different theories of encoding interference. What's revolutionary about this approach is that one is forced to make a commitment about one's theories; no more vague hand gestures. The limitations of what one can learn from data and from the models is always going to be an issue---one never has enough data, even when people think they do. But in our paper we are completely upfront about the limitations; and all code and data are available at https://osf.io/ykjg7/ for the reader to look at, investigate, and build upon on their own.
Download the paper from here: https://psyarxiv.com/957e3/
Modeling misretrieval and feature substitution in agreement attraction: A computational evaluation
Abstract
We present a self-paced reading study investigating attraction effects on number agreement in Eastern Armenian. Both word-by-word reading times and open-ended responses to sentence-final comprehension questions were collected, allowing us to relate reading times and sentence interpretations on a trial-by-trial basis. Results indicate that readers sometimes misinterpret the number feature of the subject in agreement attraction configurations, which is in line with agreement attraction being due to memory encoding errors. Our data also show that readers sometimes misassign the thematic roles of the critical verb. While such a tendency is principally in line with agreement attraction being due to incorrect memory retrievals, the specific pattern observed in our data is not predicted by existing models. We implement four computational models of agreement attraction in a Bayesian framework, finding that our data are better accounted for by an encoding-based model of agreement attraction, rather than a retrieval-based model. A novel contribution of our computational modeling is the finding that the best predictive fit to our data comes from a model that allows number features from the verb to overwrite number features on noun phrases during encoding.
Sunday, September 23, 2018
Recreating Michael Betancourt's Bayesian modeling course from his online materials
Several people wanted to have the slides from Betancourt's lectures at SMLP2018. It is possible to recreate most of the course from his writings:
1. Intro to probability:
https://betanalpha.github.io/assets/case_studies/probability_theory.html
2. Workflow:
https://betanalpha.github.io/assets/case_studies/principled_bayesian_workflow.html
3. Diagnosis:
https://betanalpha.github.io/assets/case_studies/divergences_and_bias.html
4. HMC: https://www.youtube.com/watch?v=jUSZboSq1zg
5. Validating inference: https://arxiv.org/abs/1804.06788
6. Calibrating inference: https://arxiv.org/abs/1803.08393
1. Intro to probability:
https://betanalpha.github.io/assets/case_studies/probability_theory.html
2. Workflow:
https://betanalpha.github.io/assets/case_studies/principled_bayesian_workflow.html
3. Diagnosis:
https://betanalpha.github.io/assets/case_studies/divergences_and_bias.html
4. HMC: https://www.youtube.com/watch?v=jUSZboSq1zg
5. Validating inference: https://arxiv.org/abs/1804.06788
6. Calibrating inference: https://arxiv.org/abs/1803.08393
Thursday, July 26, 2018
Stan Pharmacometrics conference in Paris July 24 2018
I just got back from attending this amazing conference in Paris:
http://www.go-isop.org/stan-for-pharmacometrics---paris-france
A few people were disturbed/surprised by the fact that I am linguist ("what are you doing at an pharmacometrics conference?"). I hasten to point out that two of the core developers of Stan are linguists too (Bob Carpenter and Mitzi Morris). People seem to think that all linguists do is correct other people's comma placements. However, despite my being a total outsider to the conference, the organizers were amazingly welcoming, and even allowed me to join in the speaker's dinner, and treated me like a regular guest.
Here is a quick summary of what I learnt:
1. Gelman's talk: The only thing I remember from his talk was the statement that when economists fit multiple regression models and find that one predictor's formerly significant effect was wiped out by adding another predictor, they think that the new predictor explains the old predictor. Which is pretty funny. Another funny thing was that he had absolutely no slides, and was drawing figures in the air, and apologizing for the low resolution of the figures.
2. Bob Carpenter gave an inspiring talk on the exciting stuff that's coming in Stan:
- Higher Speeds (Stan 2.10 will be 80 times faster with a 100 cores)
- Stan book
- New functionality (e.g., tuples, multivariate normal RNG)
- Gaussian process models will soon become tractable
- Blockless Stan is coming! This will make Stan code look more like JAGS (which is great). Stan will forever remain backward compatible so old code will not break.
My conclusion was that in the next few years, things will improve a lot in terms of speed and in terms of what one can do.
3. Torsten and Stan:
- Torsten seems to be a bunch of functions to do PK/PD modeling with Stan.
- Bill Gillespie on Torsten and Stan: https://www.metrumrg.com/wp-content/uploads/2018/05/BayesianPmetricsMBSW2018.pdf
- Free courses on Stan and PK/PK modeling: https://www.metrumrg.com/courses/
4. Mitzi Morris gave a great talk on disease mapping (accident mapping in NYC) using conditional autoregressive models (CAR). The idea is simple but great: one can model the correlations between neighboring boroughs. A straightforward application is in EEG, modeling data from all electrodes simultaneously, and modeling the decreasing correlation between neighbors. This is low-hanging fruit, esp. with Stan 2.18 coming.
5. From Bob I learnt that one should never provide free consultation (I am doing that these days), because people don't value your time then. If you charge them by the hour, this sharpens their focus. But I feel guilty charging people for my time, especially in medicine, where I provide free consulting: I'm a civil servant and already get paid by the state, and I get total freedom to do whatever I like. So it seems only fair that I serve the state in some useful way (other than studying processing differences in subject vs object relative clauses, that is).
For psycholinguists, there is a lot of stuff in pharmacometrics that will be important for EEG and visual world data: Gaussian process models, PK/PD modeling, spatial+temporal modeling of a signal like EEG. These tools exist today but we are not using them. And Stan makes a lot of this possible now or very soon now.
Summary: I'm impressed.
http://www.go-isop.org/stan-for-pharmacometrics---paris-france
A few people were disturbed/surprised by the fact that I am linguist ("what are you doing at an pharmacometrics conference?"). I hasten to point out that two of the core developers of Stan are linguists too (Bob Carpenter and Mitzi Morris). People seem to think that all linguists do is correct other people's comma placements. However, despite my being a total outsider to the conference, the organizers were amazingly welcoming, and even allowed me to join in the speaker's dinner, and treated me like a regular guest.
Here is a quick summary of what I learnt:
1. Gelman's talk: The only thing I remember from his talk was the statement that when economists fit multiple regression models and find that one predictor's formerly significant effect was wiped out by adding another predictor, they think that the new predictor explains the old predictor. Which is pretty funny. Another funny thing was that he had absolutely no slides, and was drawing figures in the air, and apologizing for the low resolution of the figures.
2. Bob Carpenter gave an inspiring talk on the exciting stuff that's coming in Stan:
- Higher Speeds (Stan 2.10 will be 80 times faster with a 100 cores)
- Stan book
- New functionality (e.g., tuples, multivariate normal RNG)
- Gaussian process models will soon become tractable
- Blockless Stan is coming! This will make Stan code look more like JAGS (which is great). Stan will forever remain backward compatible so old code will not break.
My conclusion was that in the next few years, things will improve a lot in terms of speed and in terms of what one can do.
3. Torsten and Stan:
- Torsten seems to be a bunch of functions to do PK/PD modeling with Stan.
- Bill Gillespie on Torsten and Stan: https://www.metrumrg.com/wp-content/uploads/2018/05/BayesianPmetricsMBSW2018.pdf
- Free courses on Stan and PK/PK modeling: https://www.metrumrg.com/courses/
4. Mitzi Morris gave a great talk on disease mapping (accident mapping in NYC) using conditional autoregressive models (CAR). The idea is simple but great: one can model the correlations between neighboring boroughs. A straightforward application is in EEG, modeling data from all electrodes simultaneously, and modeling the decreasing correlation between neighbors. This is low-hanging fruit, esp. with Stan 2.18 coming.
5. From Bob I learnt that one should never provide free consultation (I am doing that these days), because people don't value your time then. If you charge them by the hour, this sharpens their focus. But I feel guilty charging people for my time, especially in medicine, where I provide free consulting: I'm a civil servant and already get paid by the state, and I get total freedom to do whatever I like. So it seems only fair that I serve the state in some useful way (other than studying processing differences in subject vs object relative clauses, that is).
For psycholinguists, there is a lot of stuff in pharmacometrics that will be important for EEG and visual world data: Gaussian process models, PK/PD modeling, spatial+temporal modeling of a signal like EEG. These tools exist today but we are not using them. And Stan makes a lot of this possible now or very soon now.
Summary: I'm impressed.
Subscribe to:
Posts (Atom)